みなさん、こんにちは! Cygamesエンジニアの佐藤です。
季節も秋を迎えて、すっかり涼しくなってきましたね。
秋の夜長はのんびり箱庭ゲームなどいかがでしょうか?
SkyrimやGTAなどのオープンワールド系の箱庭ゲームでは、
街を歩くNPC達の動きも作り込まれています。
モブキャラクターたちが街や村の中で生活感豊かに動いていると、
ゲーム世界の日常の中に実際に入り込んでいるような気持ちになれますよね!
今回の記事では、NPCの生活行動のためのAIを一例にあげつつ、
自律エージェントの考え方に基づいたキャラクター駆動の仕組みについて
御紹介したいと思います。
Ⅰ.自律エージェントとは?
周囲の環境を認識して状況を解釈し、自身の内的な方針に基づいて意思決定を行って、
環境に働きかける行動を取る能力を持つ存在を自律エージェントと呼びます。
わかりやすく、ゲームの敵キャラクターに置き換えて考えてみましょう。
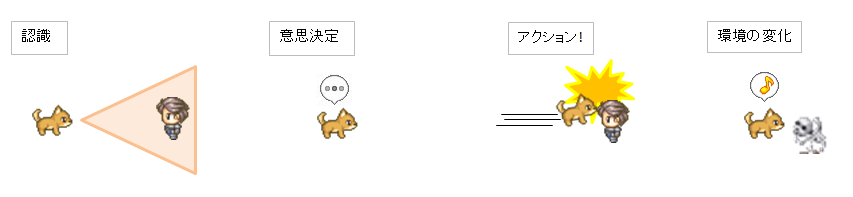
Step1. 周囲の環境を認識
マップ上を徘徊する敵モンスターの狐は、
周囲の環境を視認することでプレイヤーの存在を認知します。
狐は知覚した情報から、『外敵が目の前にいる』という主観的な解釈(認識)を形成します。
Step2. 内的方針に基づいて意思決定
「外敵を排除する」というモンスターとしての方針に基づいて、
何を行うかを計画します。
Step3. アクション
計画に基づいて、行動を行います。
狐はプレイヤーに駆け寄り、体当たりを行いました。
Step4. 行動の結果、環境が変化
狐の行動により環境に変化がもたらされます。
プレイヤー(環境内要素)は負傷し、墓場送りとなりました。
思ったより簡単そうですね!
『認識と自身の方針に基づいて、何をするかを決定し、行動する』
人間が実際に行うのと似たような思考フローを辿るので、
自律エージェントの考え方を上手く適用できれば、
キャラクターの動かし方を考えやすくなりますよ。
Ⅱ.ワークケース
ここからは、簡単なワークケースに沿って
エージェントベースのアーキテクチャのゲームへの適用例と
AIの設計の過程についてみてみます。
今回のお題は「箱庭ゲームにおけるモブ、村人NPC」です。
AIの要件として、どのような事項が考えられるでしょうか…。
考えられる要件
■量産性
オープンワールド系の箱庭ゲームは開発規模も大きくなりがちです。
登場する一般NPCの数も膨大となるため、
必要な品質を確保しつつ、少ない工数で量産するための工夫が必要になってきます。
■拡張性・整備性
キャラクターの行動調整は特に試行錯誤を要する部分ですので、
開発規模の大きなゲームでは、拡張性や整備性への配慮も重要になります。
■多様性の確保
無個性の代名詞のようなモブNPCですが、
群衆表現を行っているゲームのNPCなどを観察すると、
真の意味で無個性なモブNPCは存在しないことがわかります。
雑多性や生活感の感じられる集団の演出は、
小さな個性のゆらぎを持った多様なNPCが寄り集まることで実現されます。
なにより、その世界で生きる人々のちょっとした個性の違いや、
バックボーンが垣間見えるとぐっとゲーム世界の奥行きが増しますよね!
■生活感
村人のようなモブNPCは世界の日常を形作る要素です。
生活感の感じられる行動をAIに取り込むことができると面白そうです。
■有機性・インタラクティブ性
プレイヤーが一つの拠点で日常を繰り返すようなゲームを考えた場合、
その街に登場するNPCが、毎日一分一秒違わず定刻通りに
全く同じ行動を取り続けるというのは、少々味気ありません。
ある程度はNPCが自由意思をもって行動しているよう、
見せかける工夫ができると良さそうです。
特にプレイヤーからのなんらかの働きかけに関しては、
ゲームのインタラクティブ性を確保する意味でも、
しっかりとNPCからのリアクションを返していけるよう、
AIの構造を考えておきたいところです。
キャラクターの仕様
上記の要件を念頭に、キャラクターの仕様とAIの設計を切ってみます。
考えやすいように、下記のような簡単な生活行動を行うNPCで考察してみましょう。
【キャラクター設定】
エージェントのA子は森にすむりんご売り。
森で集めたりんごを売って、日々生計を立てている。
【行動ルール1】
集めたりんごを出荷箱に入れると、お金が手に入る。
※りんごはマップ上に自動でポップ
※A子が一度に運べるりんごは3個まで。
【行動ルール2】
A子は疲れると部屋に戻って、ベッドで休む。
【行動ルール3】
A子はおなかが減ると、りんごを食べて飢えを満たす。
エージェントの動作イメージ 概観
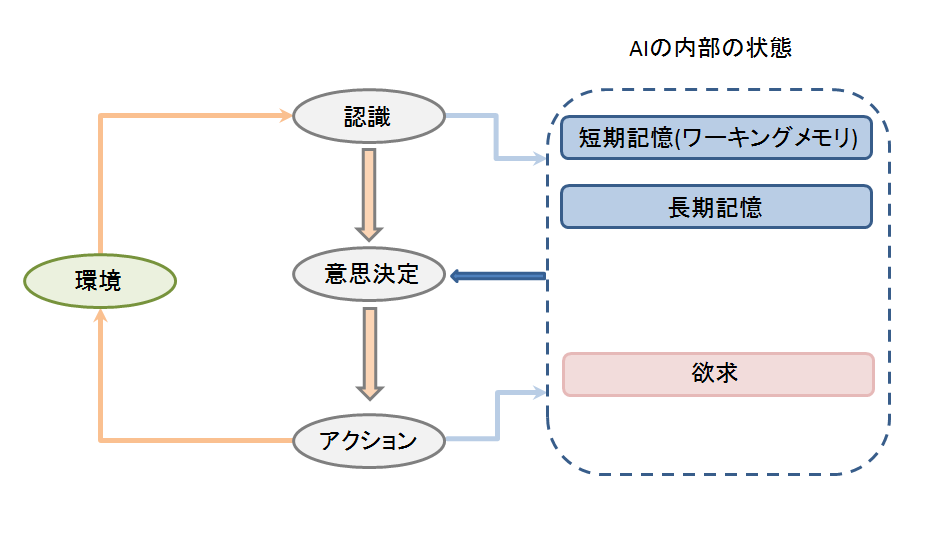
自律エージェントの考え方をベースに、おおまかなAIの構造を考えてみます。
最初に紹介した動作フローを通じて、AIの内部の状態と環境が相互に作用する構造です。
また、AIが認知した情報などを格納するための場所として、
内部に記憶のための領域を用意しました。
短期記憶には発見したりんごの位置などの
すぐに忘れてしまうような一時的な情報を、
長期記憶には、部屋にある家具の情報など、
キャラクターにとっての恒久的な情報を格納します。
記憶の構造をAIに持ち込むことで、どのような効果が生まれるのでしょうか…
少しワクワクしませんか?
意思決定の手法をデザインする
1.プランニングの方法について設計する
(1).最上位の目標を定義する
『「今何をしたいかを判断して行動方針を決定し」そのための「行動計画」を立案する』
機能の実装方法について考えてみましょう。
まずはAIが選択する行動方針となる一番大きな目標について、洗い出してみます。
AIに行わせたい行動を踏まえると、下記の3つが定義できそうですね。
・お金を稼ぐ
・ベッドで休む
・りんごを食べる
(2).目標をさらに小さな目標に分解してみる
洗い出した目標ですが、もう少し具体的に考えるために、
更に小さな目標に分解してみます。
たとえば『お金を稼ぐ』は…
お金を稼ぐ
→りんごを集める
→りんごを出荷する
のように分解できそうですね。
(3).もっと分解!
更に分解してみましょう。
お金を稼ぐ
→ りんごを集める
→ りんごを探す
→ 見つけたりんごの場所まで行く
→ りんごを拾う
→ りんごを出荷する
→ 出荷箱の元まで行く
→ りんごを出荷箱に入れる
最終的には、キャラクターが実行するアクションの粒度になるまで分解します。
こうして出来上がった目標の順列を順番に解決していけば、
最終的に「お金を稼ぐ」という目標を達成することができそうですね。
実はこれが「お金を稼ぐ」という目標を達成するための「行動計画」になります!
実行イメージを見てみましょう。

目標を適宜小さな目標に分解しながら、一つ一つ解決していく形で行動しています。
一見複雑な手順が必要に見える行動も、このように見ていけば単純化して解決できますね!
同じように他の目標についても分解を行って、
必要となる目標とアクションについて洗い出していきましょう。
(4).ゴールベースプランニングについて
このように目標をベースにAIのプランニングを考える手法を
ゴールベースプランニングと呼びます。
ゴールベースプランニングには下記のようなメリットがあります。
【ゴールベースプランニングのメリット】
・人間がプランを立てる際の思考過程に近いロジックであるため、デザインが容易。
・階層ごとにAIの思考の段階を切り分けることができるため、
スケーラビリティが確保しやすい。
・目標単位での思考をパッケージ・部品化できるため、
思考の組換えや使いまわしが容易。
・長期的なスパンでの計画の立案と解決が可能。
2.プランの評価指標を設計する
(1).欲求を定義する
数ある行動プランの中から、一つのプランを選び出そうと考える場合、
AIがそのプランを評価するための指標が必要になってきます。
AIが行う生活行動に紐づく指標として、
下記のような欲求の充足度を設定してみましょう。
・食欲
・睡眠欲
・金銭欲
充足度は時間の経過とともに減ることにして、
食欲の充足度が減ったら「りんごを食べる」目標を設定。
「りんごを食べる」目標を達成すると食欲の充足度が回復するといった具合です。
プランの選択部分を素直に仮想コードに落としてみると
下記のような形になるでしょうか…。
if( 食欲の充足度 < 閾値 ){
// 「りんごを食べる」目標を設定
}else if( 睡眠欲の充足度 < 閾値 ){
// 「ベッドで眠る」目標を設定
}else if( 金銭欲の充足度 < 閾値 ){
・
・
・
一見、このままでも上手く動きそうな気がするのですが…
(2).プランに報酬を設定( 意思決定のロジックとプランの分離 )
先のコードの実装は、後々の拡張のことを考えるとあまり良い実装ではありません。
行動プランの追加は十分考えられることですし、その度に分岐を追加したり
分岐条件を調整したり…というのは、大量生産が必要となるNPCにおいては少々管理が煩雑です。
分岐の境界条件が明確であるため、規則的な動きになりがちですし、
開発工数が大きくなるほど、AIの調整に融通が利きにくくなります。
そこでプランに対して報酬(欲求の充足の度合い)を設定し、現在の欲求に基づいて報酬を評価。
評価の一番高い行動を選択する、という形にアルゴリズムを変更してみましょう。
//コードイメージ(C#)
*プランのデータ構造
class Plan {
public GoalType goalType; // 実行する目標の種別
public List<Reward> rewardProspects; // 報酬の見込み
}
*意思決定のロジック
//実行可能なプランをリストアップ
List<Plan> plans = EnumerateExectablePlans();
//最も評価の高いプランを算出
float maxValue = 0;
Plan execPlan = null;
foreach( var plan in plans ){
//プランを現在の欲求と、プランの報酬に基づいて評価
float value = EvaluatePlan( plan );
if( value >= maxValue ){
execPlan = plan;
}
}
//一番評価値の高かったプランの目標を設定
これなら、後々にプランが追加されても意思決定のロジックは変更せずに済みますね。
同じ食欲を満たす行動プランでもバリエーションを持たせることが容易になりますし、
複数の欲求を同時に満たす行動プランを織り交ぜることもできます。
行動プランと報酬を外部に分離してデータドリブン化できるので、管理も楽になりそうです!
(3).【応用】プランをオブジェクトに紐づける
プランを意思決定のロジックと分離することによるメリットについて、
もう少し詳しく見てみましょう。
分離されたプランの情報をベッドなどのオブジェクトに紐づけ保有させます。
視認したオブジェクトは記憶に保存するものとし、
実行可能なプランをリストアップする際に、
記憶に保持されているオブジェクトに紐づいているプランをリストに追加するよう、
処理を付け加えてみます。
//コードイメージ(C#)
*オブジェクトのデータ構造
class Object {
public ObjectType type; //オブジェクト種別
public Vector3 position; //オブジェクトの位置
public Plan plan; //行動プラン
}
*実行可能なプランをリストアップするための関数
List<Plan> EnumerateExectablePlans() {
List<Plan> plans = new List<Plan>();
//記憶に登録されているオブジェクトを列挙
List<Object> objects = EnumerateMemolizedObjects();
//オブジェクトに紐づいたプランを、リストに追加
foreach( var object in objects ){
plans.Add( objects.plan );
}
・
・
・
}
実行イメージを見てみましょう。
さて、どのような効果があるのでしょうか?
部屋に新しい家具(本棚)が追加されていることを発見することで、
自然と本棚に関連する行動(本を取り出して読む)をとるようになっています。
外部の環境の変化と、それに伴う認識の変化に合わせて、
有機的に対応を変化させるAIになりました!!
今後、AIの行動に影響を与えるような新しいオブジェクトが追加されたとしても、
意思決定のロジックに手を加える必要はないため、拡張も容易です!
記憶の構造を取り入れることで、
デモのように『自分の記憶にないオブジェクトを発見した時に訝しがる』行動を
取らせることができるので、キャラクターの感情表現の幅も広がりますよ。
ちょっとした工夫でAIの表現力や、開発効率がぐっと変わってくるところが面白いですね。
(4).アフォーダンス
オブジェクトにプランを紐づける考え方について、もう少しだけ詳しく見てみましょう。
認知心理学の概念の中には、
「椅子」という物体を認識した時、
私たちは同時に『椅子が保有する「椅子に座る」という行為の可能性』を知覚している
といった考え方があります。
この物体が持つ知覚可能な「行為の可能性」のことをアフォーダンスと呼びます。
上で述べた例だとObject構造体が持つplanの情報が
アフォーダンスに相当することになりますね。
アフォーダンスの考え方を用いると、
環境とキャラクターとのインタラクションを考えやすくなります。
何気ない学びの中にもゲームのキャラクターの動かし方に活用できる考え方、
ヒントが潜んでいると考えると、ほんの少しワクワクしてきませんか?
(5).欲求の減少速度を変更してみる
ここでもう一人、食いしん坊な「B子」を登場させることを考えてみます。
B子は食いしん坊ですので、食欲の減少速度をA子よりも速くしてみましょう。
食欲の減少速度を速めれば、食欲を満たすための行動を頻繁にとるようになります。
パラメータの調節により、キャラクターの性格設定を行動傾向に反映させることできるので、
様々な個性のモブNPCを用意することも容易に行えそうですね!

(6).ニーズベース
このように、行動プランがAIにとってどのような効用をもたらすか?に着目して、
意思決定を行う手法をユーティリティベース、
その中でも特に評価の指標として欲求を利用するものを、
ニーズベースアーキテクチャと呼びます。
ニースベースアーキテクチャはキャラクターの個性をAIに組み込むにあたって
色々と応用のきく面白い構造ですので、
今後のブログの記事でも、もっと詳しく見ていければと思います。
(7).報酬の評価について(評価関数の設計)
最後に報酬の評価方法について軽く見ておきましょう。
評価の関数の設計を少し工夫するだけでも、AIの動き方は変わってきます。
たとえば…
(1.0 – 欲求の充足度) × (報酬)
で評価値を求めた場合、
充足度が減るほど、線型に行動プランの評価が高くなっていきます。
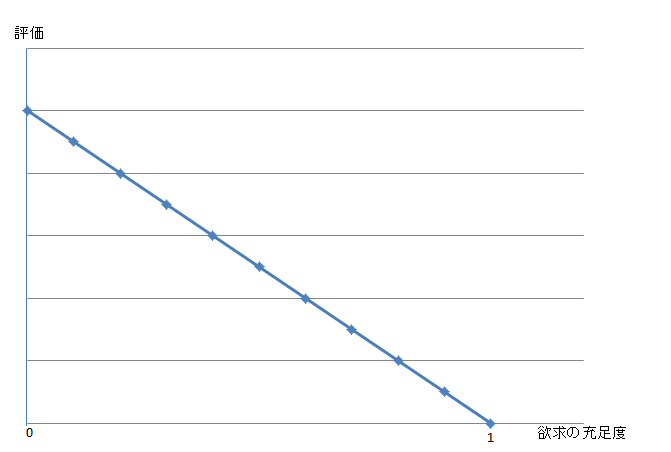
ここで数式に少しだけ、手を加えてみましょう。
(1-欲求の充足度)の『3乗』 × (報酬)
さて、どうなるでしょうか?
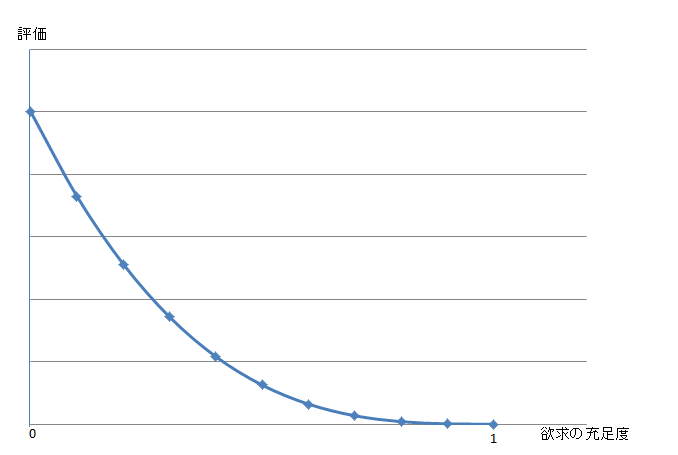
充足度があまり減っていないときの変化は緩やかに、
充足度が0に近くなるほど、評価の伸びが大きくなるようになりました。
切羽詰まった状況(おなかが減って飢え死にしそうなとき、とか)になるほど、
関連する行為(ものを食べる、など)の価値が劇的に高まる、というわけですね。
色々なカーブのグラフで、どのように
キャラクターの動きが変わるか試してみるのも楽しいですよ!
評価の結果は影響マップの時と同じく0.0~1.0の間に収まるよう正規化しておきましょう。
複数の指標の評価を組み合わせるときに、基準が統一されるので調整しやすくなります。
おまけ 影響マップを活用したフィールドの探索
りんごを探して森を探索する動きの表現方法について考えてみます。
あらかじめ決め打ったルートを巡回させる形でも良いのですが、
せっかくですので前回ご紹介した影響マップを利用して、
もう少し有機的に探索を行っているように見えるよう工夫してみましょう。
1.視認済みの領域を記憶する
用意する影響マップは二つです。
(1)A子からの距離を正規化した距離マップ( A子に近いほど評価が高い )
(2)視認済みの領域に0、まだ視認していない領域に1を書き込んだマップ
↓
(1)と(2)を乗算!
あとは前回と同じく評価の高いセルへの移動を繰り返すよう、
処理を組んでみます。
どのような動きになるでしょうか…。

まだ探索していない領域を埋め立てるようにぐるっと巡回する動きになりました!
2.視認済みの領域の評価値を時間とともに回復させる
このままだと、毎度同じ巡回ルートをたどることになりますし、
巡回済みの領域にりんごがポップした場合などに対応できませんので、
もう少しだけ手を加えてみます。
(1)視認済みの領域の値を0にしたマップの評価値を、時間経過とともに徐々に回復させる
(2)記憶内に未回収のりんごの位置がある場合は、その位置に向かうことを優先

直近で向かった場所は避けてウロウロと探し回りながら、
ある程度時間が経った場所には再度探索に向かうようになりました!
「持ちきれないりんごがあった時に、
その位置を覚えておいて後で回収に向かう」という挙動が、
乱数要素として働くため、より有機的な動きに見えます。
キャラクターの行動としても納得感がでてきますよね!
考えてみよう!
「複数のキャラクターで分担して、フィールドを探索」するにはどうしたら良いでしょうか…
ちょっとした工夫の追加で色々な表現が実現できると思うので、
良ければ考えてみてくださいね。
終わりに
エージェントベースアーキテクチャ、いかがだったでしょうか?
今回ご紹介した以外にもエージェントベースでの
キャラクターの動かし方には様々な方法があります。
少しづつご紹介していければと思いますので、
皆さんと一緒により良いキャラクターの動かし方について、考察を深めていければ嬉しいです!