Cy#の河合です。今回新しくオープンソースライブラリとして、マスターデータの管理用途を主眼に置いた、読み取り専用のインメモリデータベースを公開しました。
[GitHub – Cysharp/MasterMemory]
今までのゲーム開発の経験から、「省メモリ(インメモリということもあり使用メモリ量には気を使う」「高速なデータベースロード(構築に時間がかかるとゲームの起動速度に大きく影響する)」「高速な検索(ディクショナリのルックアップと同程度のクエリ)」の3点を重視して作りました。以下がベンチマークの結果となります。
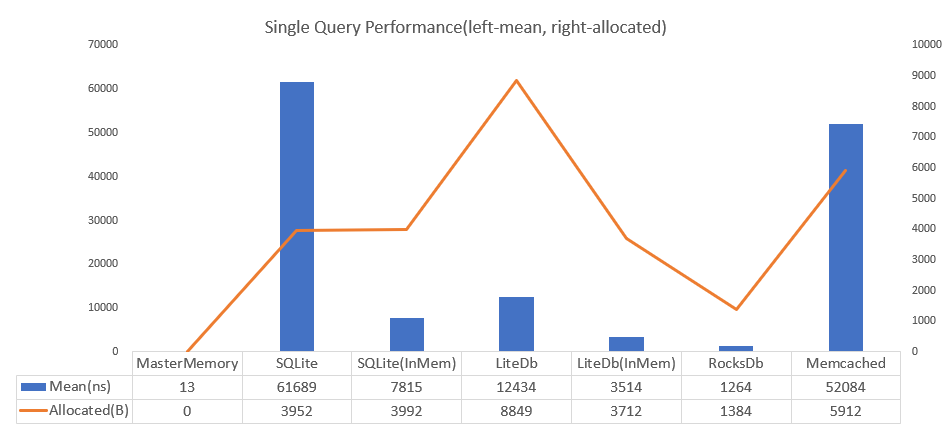
MasterMemory、SQLite、LiteDB、RocksDBがインプロセス、Memcachedのみ別プロセスのマシン内通信による比較です。SQLite(ファイル読み込み型)の4700倍高速で、1クエリでのアロケーションはゼロです。また、保存時のファイルサイズも極小です(十分小さい場合、更新があった場合に丸ごとCDNに載せて置き換えるだけにする、などで運用が楽になります)。
Unityで使用できるほか、サーバーサイドでも .NET Coreアプリケーションでも同様に活用できます。サーバー利用時の比較として同一マシン上にMemcachedを立てて通信するような場合とも比較しましたが、もちろん圧倒的に高速です。
「すべてインメモリの読み取り専用」と割り切ることにより内部構造がシンプルになり、これにより、クエリのための中間オブジェクト生成、通信、データのデシリアライズ、インデックスと実データの結合、ロックなど、多くの処理を省くことが可能になっています。また、単純なインプロセスのハッシュテーブル(Dictionary)と比べても、使用メモリ量が少なく、構築時間が早く、「レンジ検索、近傍検索、複数キー、セカンダリインデックス」といった多くの機能を持つなど、より良い性能特性を持ちます。
同じようなコンセプト(embeddable write-once key-value store)としてLinkedInが開発したPalDBというものがありますが、実装も性能特性も全く異なります。
完全な型付け
C# to C#によるコード生成によって、データベースへの操作は完全に型付けされています。
public enum Gender
{
Male, Female, Unknown
}
// 要素のクラスを作る
[MemoryTable("person"), MessagePackObject(true)]
public class Person
{
// 属性でインデックスを定義する
[PrimaryKey]
public int PersonId { get; set; }
[SecondaryKey(0), NonUnique]
[SecondaryKey(1, keyOrder: 1), NonUnique]
public int Age { get; set; }
[SecondaryKey(2), NonUnique]
[SecondaryKey(1, keyOrder: 0), NonUnique]
public Gender Gender { get; set; }
public string Name { get; set; }
}
// ---
var db = new MemoryDatabase(File.ReadAllBytes("db.bin"));
// .PersonTable.FindByPersonIdもコード生成により型が付いてる
Person person = db.PersonTable.FindByPersonId(10);
事前の自動生成ベースにすることは、APIとしての使い勝手の向上のほか、性能特性の改善にも寄与しています。
欠点は、必ずコード生成という煩わしい手段が必要になることです。コード補完など、型が付いていたほうが利便性が高くなり、もし自動生成しないと、安全性が欠けたうえに手書きコード量が多くなると考え、コード生成を前提にしています。また、Unityの場合は内部データの保持にMessagePack for C#を使っている都合上、そちらでのシリアライザ自動生成も必要になっているので、どうせ一つやるならもう一つ追加で、といった精神も少しあります。
検索手段には柔軟性があり、非ユニークの場合はRangeView<T>という範囲を表すコレクションが取得できるほか、多値をキーにする、範囲検索する、近くの値を検索するなどが可能になっています。
// .PersonTable.FindByPersonIdもコード生成により型が付いてる Person person = db.PersonTable.FindByPersonId(10); // 女性の23歳を取得。戻り値は複数。 RangeView<Person> result = db.PersonTable.FindByGenderAndAge( (Gender.Female, 23)); // 31歳に最も近い人を取得 RangeView<Person> age1 = db.PersonTable.FindClosestByAge(31); // 20歳から29際の人を取得 RangeView<Person> age2 = db.PersonTable.FindRangeByAge(20, 29);
有効なインデックスにはすべて型が付いているため入力補完に従うだけで対応できるほか、誤ったクエリを書いてしまう可能性もありません。
ジョインに関しては、クエリが非常に高速なのでLINQ to ObjectsでDictionary感覚で使って結合してしまって構いません。
var result = responses
.Select(x => new
{
Name = db.MonsterTable.FindById(x).Name,
x.Level,
Power = db.MonsterPowerTable.FindById(x).Power
});
といったような具合です。
理論上最小のメモリ使用量と自動インターン化
実際にメモリ中に保持し、使用するデータ(T)は、データベース構築時にヒープ上に生成されます。そして、実データの集合(T[])以外のデータは保持しません(セカンダリインデックスを使用しない場合)。つまり、この場合のメモリ使用量は理論上最小となります。
また、データベース構築時に文字列は自動でインターン化するため、データ中に非正規化されている文字列データが存在する場合、他の手法に比べて圧倒的に省メモリとなっています。
例えば、
| Name | Lv | Power |
| ゴブリン | 1 | 10 |
| ゴブリン | 2 | 15 |
| ゴブリン | 3 | 19 |
| ゴブリン | 4 | 22 |
| ゴブリン | 5 | 23 |
というようなデータがある場合、「ゴブリン」という文字列は、メモリ中に5つが個別に存在します。つまり「ゴブリンゴブリンゴブリンゴブリンゴブリン」というサイズのメモリを使っています。しかし、同一文字列であることはわかっているので、メモリ中に1つの文字列とその参照だけで済むはずです。それを解決する手法が文字列のインターン化で、インターン化するとたとえ10000個の「ゴブリン」という文字列が出現しても、1つ分のメモリだけで済みます。
非常にアグレッシブな手法ですが、MasterMemoryは、一度構築したらアプリケーションの生存期間中はずっと不変で保持し続けるためのデータベース、という前提を持っているため自動でインターン化しても問題は起こりません。
実装面ではMessagePack for C#の柔軟なカスタマイズ性を生かして、データベース構築時 = デシリアライズ時に処理をフックしています。もちろん、自動インターン化は無効にすることも可能です。
差分更新
データベース自体は読み込み専用ですが、更新データを別途受信した際に、差分から新しいデータベースを作成することができます。
// 元のデータからBuilderを作り
var builder = db.ToImmutableBuilder();
// PrimaryKeyで比較して差分のみ追加/置換したり
builder.Diff(addOrReplaceData);
// PrimaryKeyで削除したり
builder.RemovePerson(new[] { 1, 10, 100 });
// そもそもまるごと入れ替えたりして
builder.ReplaceAll(newData);
// 新しいデータベースが作れます
var newDatabase = builder.Build();
例えばゲームのリアルタイム通信(弊社開発のMagicOnionのようなサーバーアプリケーション)を実装している際に、マスターデータの更新があってグローバルのマスターデータは更新したい、けれど1ゲーム内のデータは前のデータのまま使っておきたい、といった場合に、グローバルに保持しているデータベースを都度参照せずに、参照を保持しておけば、差分更新によって作られる幾つものバージョンのデータベースを保持し続けられます。
// 1ゲームにつき1つのManagerインスタンスとした場合
public class GameManager
{
MemoryDatabase database;
// 1ゲーム開始時に、「その時点」でのデータベースを確保して使う
public GameManager(MemoryDatabase database)
{
this.database = database;
}
}
グローバルなデータベースはDIコンテナのシングルトンか、静的プロパティか、何れにせよシングルトンで保持しておくと良いでしょう。
まとめ
大仰にセールストークをしましたが、実態はなんてことはなく、ただの「ソート済み配列」を「二分探索」しているだけ、です。データベースの構築が高速なのは、シリアライズされたソート済み配列をデシリアライズするだけで完了するからであり、メモリ効率が良いのは、保持しているのが実体の配列のみだからです。
それをAPI面でデータベースライクに使えるように整理していること、(最も多いユースケースであるプライマリインデックスでのプリミティブキー検索時に)C#的な実装上の工夫によりハッシュテーブル引きに近い速度を叩き出していること、C#最速のバイナリシリアライザであるMessagePack for C#の活用による高速な展開やバイナリサイズの縮小を果たしていること、などの工夫によりデータベースとしてパッケージングしています。
とはいえ、そうした見せ方というのは大事な話で、MasterMemoryの存在によって、マスターデータの取り扱いについて一定の答えを示せたのではないかと思います(少なくともパフォーマンス的に厳しいものが選択肢に上がるのはなくなって欲しい……)。別にDictionaryで良くね? という点に関しては、ゲーム開発が進んでマスターデータが巨大になった場合に、構築に時間がかかる(ハッシュテーブルを作るコストは意外と安くない)ことと、メモリ使用量(ハッシュテーブルはデータ構造としてはかなり大きめ)、そして検索が1:1のKeyValueのみで柔軟性がないこと(困ったら全件検索、が多発するとかなり効率悪い)が、以前のゲーム開発ではネックになっていました。
クライアント用途(Unity)、サーバー用途(.NET Core)ともに耐えうる仕様ですので、ぜひお試しを。どちらか片方でも十分使えますが、両方合わせると、取り得るアーキテクチャの選択肢の幅が広がるので、そちらも検討してもらえれば幸いです。また、Cy#では導入にあたってのサポート、コンサルティングもお請けできますので、ご興味がありましたらCy# – お問い合わせフォームよりコンタクトください。