こんにちは。
サーバーサイドエンジニアの浦谷・大橋です。
2022年11月16日〜18日に開催された「 db tech showcase 2022 Tokyo」において、『「最高のコンテンツ」を支える、Cygamesのデータベース技術の今までとこれから 〜次世代データベース「TiDB」の検証を開始したCygamesの取り組み〜』と題した講演を行いました。
ご参加・ご視聴いただいた皆様・コメントをくださった皆様。本当にありがとうございました。
講演資料は以下となります。
(講演当日は発表できなかった「おまけ」もChapter2の最後に追記しております)
本稿では講演でお伝えし切れなかったことや、質問をいただいた事項をフォローアップしていきます。
Chapter1フォローアップ
サーバーサイド サブマネージャーをしている大橋です。
Chapter1では、Cygamesでのデータベースの運用事情やサーバーサイドにおけるマインドを中心に、なぜTiDBへの取り組みを行っているのかをお伝えしました。
次世代データベース「TiDB」を選択したことについて
講演の中で「スケーラブル」にポイントを絞り説明させていただいた以外にも、他のプロダクトにはない特徴があると考えております。
1点目は、オープンソースでありコミュニティが活発かつ全てがオープンという点。
私たちは、今までもこれからもプロダクトの性能を引き出すチャレンジをしていきます。そのためオープンソースでありコミュニティが活発でサポートも充実している点を非常に重要だと考えています。
2点目は、運用環境が多様であること。
私たちは、オンプレ環境・クラウド環境をタイトルごとに選択して利用しております。よって、クラウドのみならずオンプレでの運用も考慮できることも大きな特徴だと考えております。
チャレンジを支える4つのマインドについて
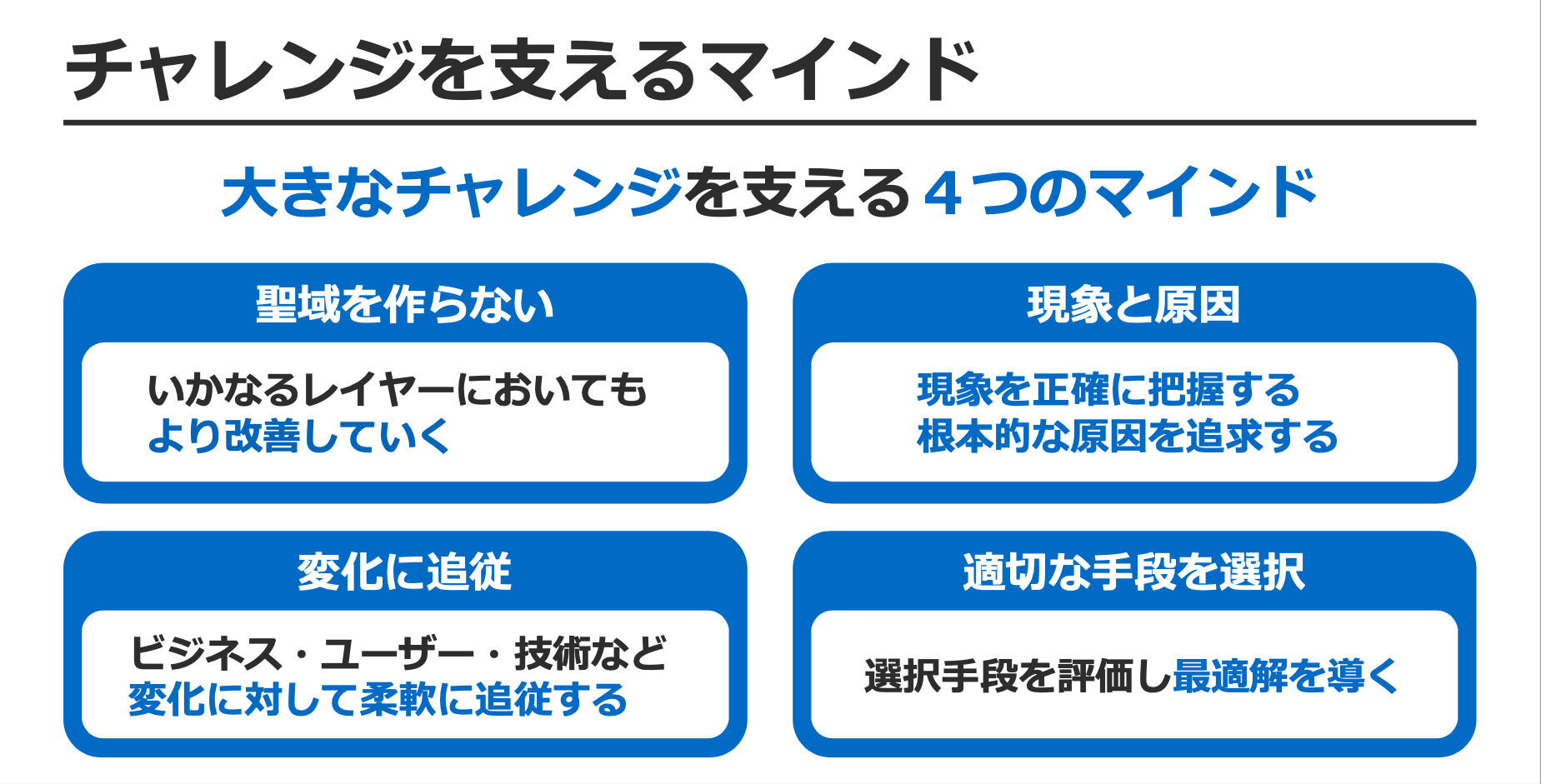
こちらの4つのマインドは、過去の講演「グランブルーファンタジーを支えるサーバーサイド技術」にて、チューニングの考え方としても紹介させて頂いたことがあります。
(その時の資料はコチラからご覧ください)
様々な状況で活用できるマインドだと思いますので、この場をお借りして説明します。
聖域を作らない
「最高のコンテンツ」を進化させることが共通認識としてあり、そのためにはいかなるレイヤーであろうがチャレンジする必要があります。
現象と原因
現象を正確に把握することで根本的な原因追求に繋がります。そして課題を正確に捉えることができ、適切な手段を選択することが安定・高速なサーバーシステムにつながります。
変化に追従
「ビジネス環境・ユーザー動向・モダンな技術スタック」など、我々を取り巻く環境には様々な変化があります。それらの変化に引っ張られるのではなく、むしろチャンスと考えて必要に応じて追従していきます。
適切な手段を選択
「課題の解決・モダンな技術への挑戦・開発言語の選択」など手段の選択はさまざまなシーンで求められます。ビジョンやミッションに沿った上で、そして正確にゴールを見据えて最適解を導くことが重要です。
以上の様に、私たちはマインドあってこその技術スタックであると考えています。私たちが継続的に改善を行い、そしてチャレンジを行うことが「最高のコンテンツ」を進化できる背景だと考えてます。
Chapter2フォローアップ
シニアデータベースアドミニストレーターをしている浦谷です。
自分からは「Chapter2 TiDBへの取り組み」についてお伝えしました。
主には「TiDBの検証について」の内容になります。
それでは早速Chapter2の内容についてフォローアップさせていただきます。
と…その前に「db tech showcaseへの想い」を話させてください。
db tech showcaseへの想い
自分が初めて聴講者としてdb tech showcaseに参加したのは、2015年に開催された「第4回目」からです。
場所は「秋葉原UDX Conference」で6月開催でした。
(その後の開催月は「7月→9月→10月→11月」と変動して調整されています。聴講者や登壇者が参加しやすく柔軟に調整している運営側の努力が素晴らしいと感じています)
その後、2020年はコロナ禍となりオンライン開催、そして2022年はオンライン・オフラインのハイブリッド開催でした。DBAであれば1度は登壇したいカンファレンスであるdb tech showcase。ずっと憧れていたdb tech showcaseへ登壇出来た事をとても感謝しています。
改めてChapter2フォローアップ
さてさてそれでは本題です。
これからChapter2のフォローアップをしていきます。
本格的にTiDBの研究に着手し始めたのは2021年6月頃からになります。
まずはTiDBの環境を構築してみよう…と思ったのですが、
わからないのでとりあえずTiDBの公式ドキュメントを読むところから始めました。
この頃の自分のTiDBに対する知識は「Spanner互換のNewSQLである」くらいの知識でしたが…
いつの間にか誰のサポートも受けずにTiDBの環境を構築することができていました。
そうです。TiDBの公式ドキュメントです。
実際にドキュメントを参照いただければわかるのですが、ドキュメントが非常に見やすく充実しているため、誰のサポート受けることなく構築できることが納得いただけるかと思います。
尚、2022年07月から日本語のドキュメントもサポートされていますので、より身近になっているかと思います。
このように、ドキュメントが整備されているのは非常にありがたく大事なことです。
環境構築編
TiDBの検証環境構築について記載していきます。
各環境を構築するための考え方や負荷試験ツールでvegeta-mysqlを採用した理由などのフォローアップができればと思います。
TiDB環境構築
ドキュメントを読んで事前に手順化した上で、実際に環境を構築しました。
尚、検証もTiDB Cloudを使用すれば手っ取り早いのですが、
TiUPコマンドを使用して自分で構築することで実際の動きを確認していきます。
AWS環境構築の自動化は既に済んでいるため、EC2の環境を構築した後にTiUPコマンドでTiDB構築していきます。(ツール名は「AWS-Automation-Support(aas)」と名付けました。)
最初はTiDBのバージョン「5.0」で構築して「5.4」にバージョンアップ。
そして現時点では「6.1」で構築しています。
共にLTS(Long-Term Support)のバージョンでありますが、今後はDMR(Development Milestone Releases)でも機能検証を行なっていければと考えています。
手動でのTiDB構築が完了したらTiDB環境構築の自動化を行います。
自動化を行う理由は「環境構築→検証→環境破棄→環境構築・・・」のサイクルを簡単にするためです。
自分は必ず先に自動化してから実際の作業を行います。
(ここで少し時間をかけることになりますが長期的視野において有用です。ツール名は「TiDB-Deployment-Manager(tdm)」と名付けました。)
負荷試験環境構築
AWSの環境構築とTiDBの環境構築の自動化が済んだら検証できる訳ではありません。
検証するにはTiDBに対してQUERYを実行する仕組みが必要になります。
今回の検証においてAPIを使用した検証も候補に入れていたのですが、もっと手軽に負荷試験ができないか?と考えたときに “素のQUERYが実行できればよい・・・そうだ!!
vegeta-mysqlだ!!!”という訳で「vegeta-mysql」を採用しました。
vegeta-mysqlはファイルに格納されたQUERYを実行して、
指定したサーバーに負荷をかけてレポートを出力するベンチマークツールです。
勿論、APIでの実行においてトランザクションが長い場合は、
レイテンシーにも影響するため確認するべき内容ですが、
初回の検証であったため素のQUERYを実行して確認しました。
TiDBは分散データベースなのでvegeta-mysqlも分散させて負荷を与えられないか?と考えていました。
「vegeta-mysqlをスケールさせて魔神の如く負荷を与える仕組みさえあれば・・・」
そう思いながら作成した仕組みが「Majin-Vegeta-Mysql(mvm)」です。
QUERYとデータの準備
検証するのであれば本番環境と同等のQUERYで検証するべきと考えていたため、デバッグ環境でデバッガーさんが網羅的に遊ぶことでQUERYを出力しサンプルQUERYとして取得しています。
サンプルQUERYではQUERYの数に限りがあるためダミーQUERYを増幅するツールも作成しました。ツール名は「Random-Query-Generator(rqg)」と名付けました。
尚、ダミーQUERY生成時にダミーデータも同時に生成しています。
TiDB検証編
TiDBを検証する準備が整ったため実際に検証を実施していくのですが、
ここでは検証のアプローチに対するフォローアップができればと思います。
1台あたりのQPSを算出した理由
まずCygamesでのソーシャルゲームにおけるユーザーの動向ですが、イベントやアクティブな時間帯にアクセス数が増加して、それに伴いQUERYが増加する傾向があります。
そのためにはコネクション数を増やすことが重要であると考えていました。
TiDB serverはコンピューティングノードをスケールすることが可能なためコネクション数を増やすことが可能です。
LBを使用してバランシングすることでアクセスが均等になるのであれば「1台あたりのQPSを算出することができれば全体のQPSを管理できるのではないか?」と考えました。
シナリオを連続実行する仕組み
vegeta-mysqlには「Rate(1秒間のリクエスト数)」と「MaxCon(同時接続数)」の値があり、それぞれの値を調整することが可能です。
まずは値を調整しながら負荷を与えることを考えていきます。
1台あたりのQPSを算出するためには「1秒間のリクエスト数と同時接続数」を可変させながら最適なQPSを探し出す必要があるのですが、手動で値を変更して当てずっぽうに実行しても正確な結果は得られないと考えていたため少しずつ値(レベル)を変動させてシナリオを連続実行する仕組みを作成しました。
但し、「1秒間のリクエスト数と同時接続数」は機械的に変動させてレベルを作成しているためレベル1から実行していたら日が暮れてしまいますので、ある程度負荷の当たりを付けながら連続実行していきます。
最適なQPSを確定
シナリオを連続実行した結果「1秒間のリクエスト数=約20000、同時接続数は約900」が最適な負荷である…としていたのですが、TiDB serverのCPU使用率がフルに近いリソースを使用していたため最適なQPSを20000の80%である「16000」として調整しました。
その結果「1秒間のリクエスト数=約16000、同時接続数は約900」が最適な負荷であると確定しました。
尚、データモデルやQUERYの質にもよるため今回の検証における負荷設定になります。
TiDB serverスケール時のQPSとパフォーマンスの影響
「台数を増やした時に最適なQPS通りにQPSがでること」及び、「スケール時におけるパフォーマンスの影響」を確認します。
「台数を増やした時に最適なQPS通りにQPSがでること」ですが、台数を増やした分だけQPSが増えました。
これはTiDBがリニアにスケールできることを意味します。
「スケール時におけるパフォーマンスの影響」ですが、TiDBとTiKVをスケールさせても全く影響がないことがわかりました。
今回はTiDBを2台から9台、TiKVを3台から9台にスケールアウトした結果になりますがCPUのスパイク、QPSやレイテンシの劣化等もなく安定していました。
しかも1分もかからずにスケールが完了しています。
尚、PD serverは基本的には3台あれば十分ですので今回はスケールの対象には入れていなかったことをこちらで補足しておきます。
今回の検証におけるTiKV serverのリソース状況に関する補足
今回のセッションではTiKV serverのメトリクスは載せてはいませんでしたが、結論から言うと全然余裕な状態でした。
これはむしろありがたく、TiKV serverはステートフルのためデータを保持しますのでカジュアルにスケールする事はなるべく避けたいと思っていたためです。
一方で、TiDB serverはステートレスでありデータを保持していないためアプリケーションサーバーと同じ感覚でカジュアルにスケールできるということになります。
年表
| 開発開始 | ツール名 | 略称 |
|---|---|---|
| 2020年04月上旬 | AWS-Automation-Support | aas |
| 2021年06月中旬 | TiDB-Deployment-Manager | tdm |
| 2021年12月中旬 | Majin-Vegeta-Mysql | mvm |
| 2021年12月下旬 | Random-Query-Generator | rqg |
Chapter2フォローアップ総括
2022年のdb tech showcaseのテーマは「Data (base) Maverick Party!|データ技術の常識を突き破れ!」でした。
因みに「Maverick」の意味は「独自路線を行く人、型破りな、異端な」等の意味になります。
今回のセッションの内容が「すごくMaverickだった!!」と思って貰えたら最高です!!!
という訳で、
db tech showcaseに登壇させていただいたことは本当に感謝です。
オフラインでは満席とのことで聴講いただいた方々には感謝です!!
そして最高です!!!
Q/A
tidb cloudを使わなかった理由はなにかありますか?
TiDB Cloudを使用しない理由は特にないのですが、 強いて言えば「TiDBの環境を自分で構築することでTiDBに対して理解度を深めることができる」 と考えていたからですね。 (どの様に構築したらどの様に動くのか?を理解すること TiDBの研究を開始した時点でAWS環境の構築自動化ができていたことや PingCAPさんのドキュメントも充実しTiUPコマンドを使用した環境構築が容易であったため 「まずは実際にやってみよう」とチャレンジしました!! 今回の検証は基礎研究に近く低レイヤで実施したかったため オンプレミスを想定した環境での検証を行いましたが、 今後はTiDB Cloudを使用した検証も行っていく予定です。
最後に
「最高のバックエンドで最高のゲームを!」
私たちは「最高のコンテンツ」を支えるために、常に技術を進化させるチャレンジをしていきます。
安定・高速・スケーラブルなサーバーシステム構築、聖域を設けずに、モダンな技術を検証/導入していくことに共感頂けるエンジニアの皆様!
ぜひ弊社の扉を叩いてください。
こちらの採用ページをご確認ください。