こんにちは、インフラチームの和田です。
9月25日(水)、26日(木)にサンフランシスコで開催されたChaos Conf 2019に参加してまいりました。Gremlin,Incが主催するChaos Confは、Chaos Engineeringの事例や知見を集めた開発者向けのカンファレンスです。同社はChaos Engineeringを「Resilience as a Service」として提供する企業で、そのプロダクト名は『Gremlin』です。Day 0がブートキャンプ、Day 1がセッション、参加総数はおよそ600人ということで、昨年(およそ400名)よりも規模は拡大しています。では、Day 0とDay 1の内容について振り返ってみます。
Day 0: HANDS-ON CHAOS ENGINEERING BOOTCAMP

Day 0は、EKS(Amazon Elastic Kubernetes Service)上に構築された架空のショッピングサイトに対して、Gremlinを使用してChaos Engineeringを体験するもので、参加者は60名ほどでした。4人ずつでチームを組み、「General」「Commander」「Scribe」「Observer」のロールに別れて作業をします。「General」が全体統括、「Commander」がGremlinを操作、「Scribe」が結果の記述、「Observer」がモニタリングを行います。全体向けに簡単な自己紹介をした後、ファシリテーターが示すシナリオに対して、EKSクラスタ上にFault Injectionをしていきます。
EKS上に構築された架空サイトの構成は下記ようなマイクロサービス設計となっており、グループワークではファシリテータから示された3つのシナリオを検証しました。
- CPU使用率の段階的上昇に対してもオートスケールが実行されるか?
- 特定のServiceにデプロイされたコンテナを停止しても自律的に復旧するか?
- フロントサーバーへの段階的な遅延の上昇に対してブラウザ上ではサイトが表示されるか?
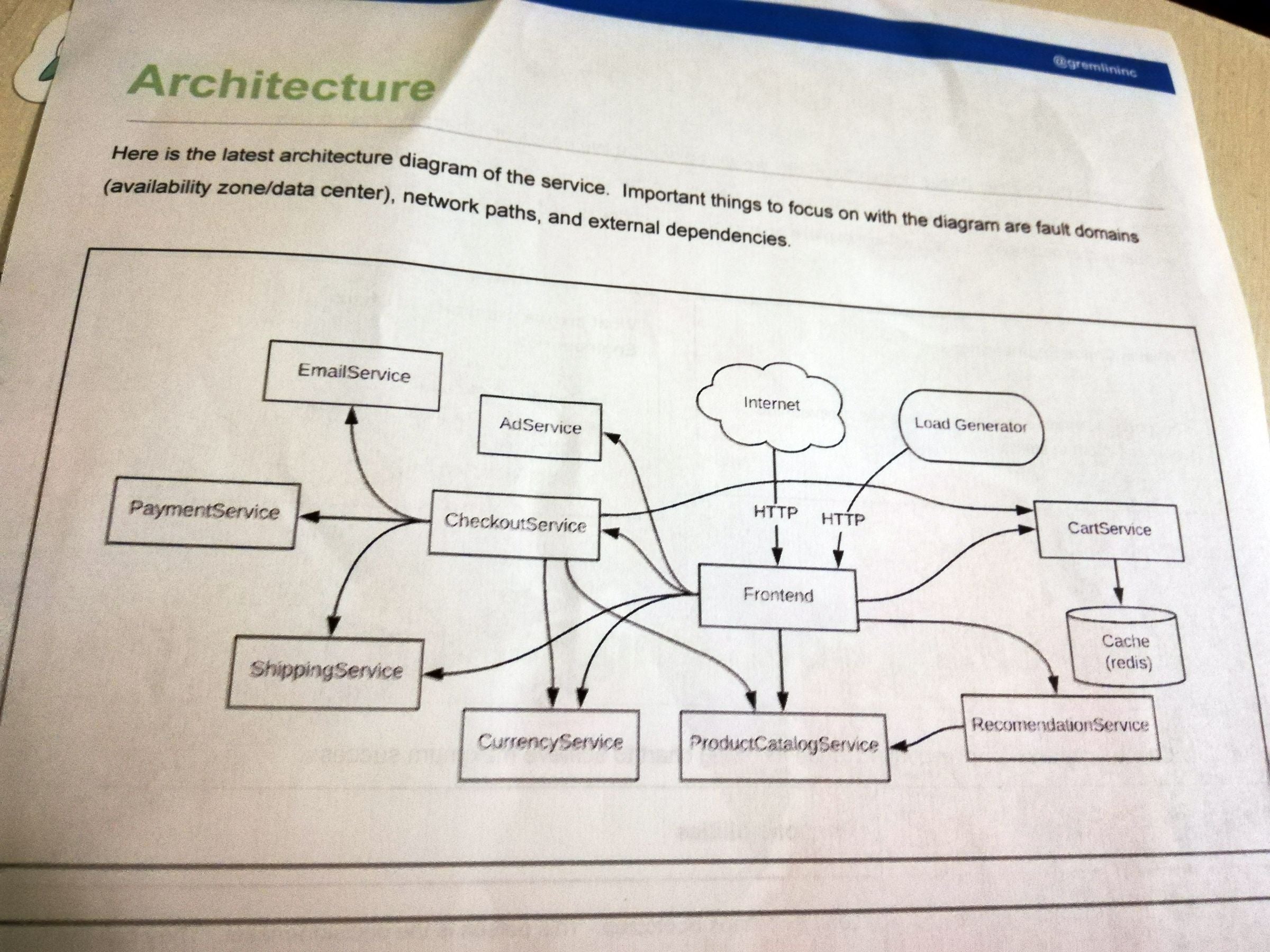
では、3つのシナリオを振り返ってみます。
1.CPU使用率の段階的上昇に対してもオートスケールが実行されるか?
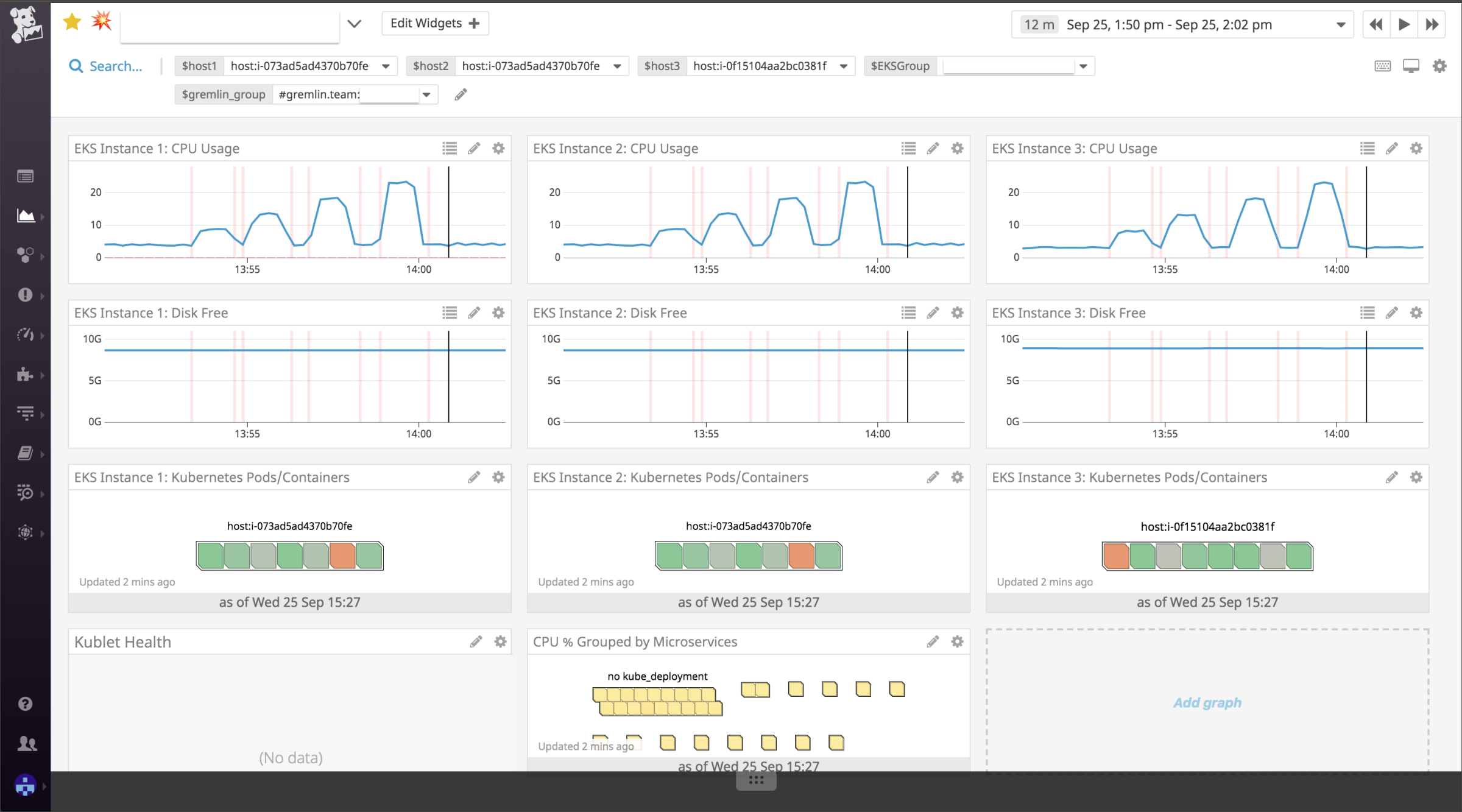
まずは、ホストのCPU使用率を20%、40%、60%⋯⋯と上昇させるシナリオです。モニタリングツールを見ると、CPU使用率が意図通りに変化しているのがわかります。ただ、一向にオートスケールはしません。後から聞いたのですが、もともとオートスケールの設定はなく、オートスケールが正しく設定されているかどうかを確認する手法としても使えることを示したかったようです。また、Datadog上では、攻撃中であることを示すバー(赤色)がグラフ上に表示されるため、実験中であること直感的にも判断しやすくなっていました。
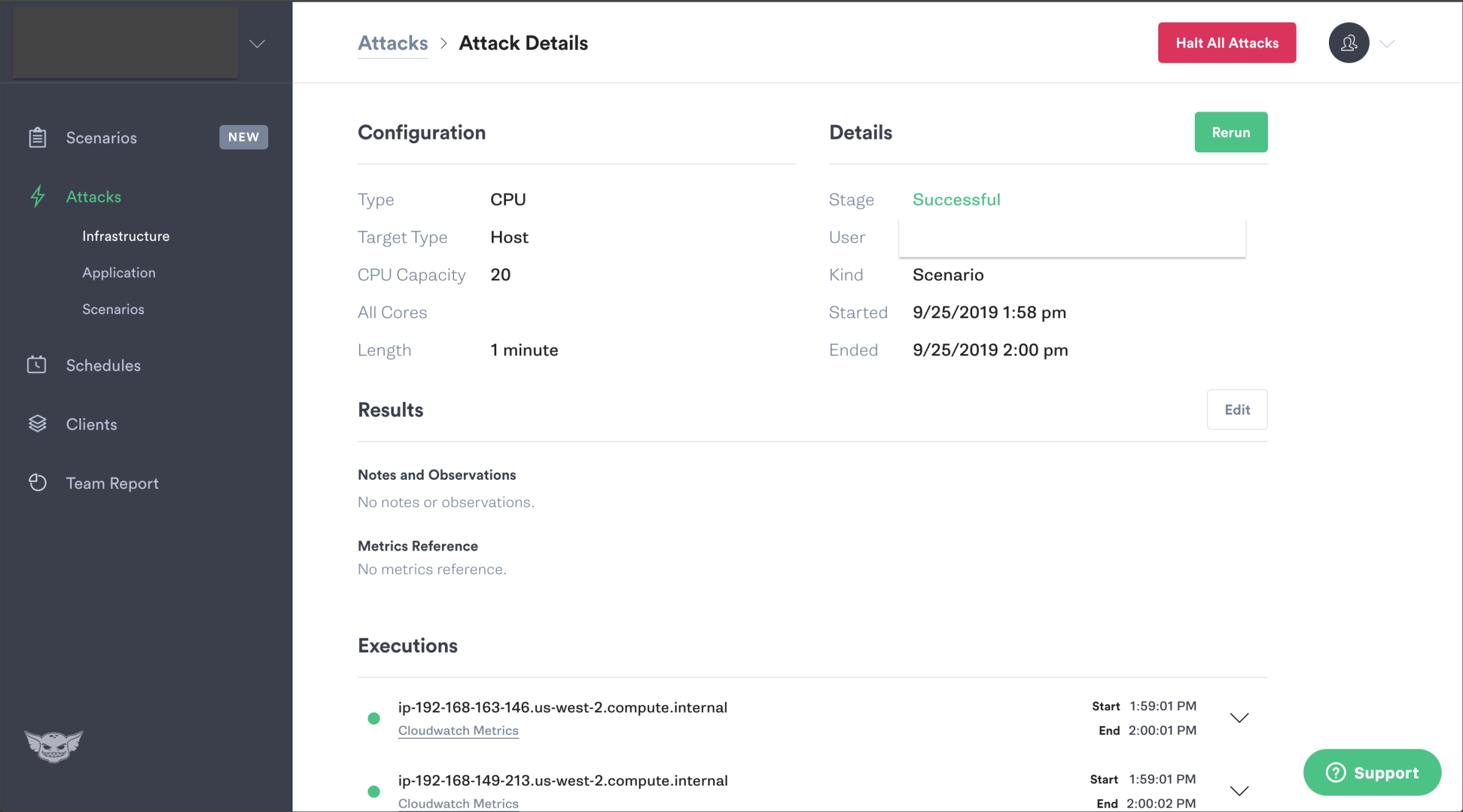
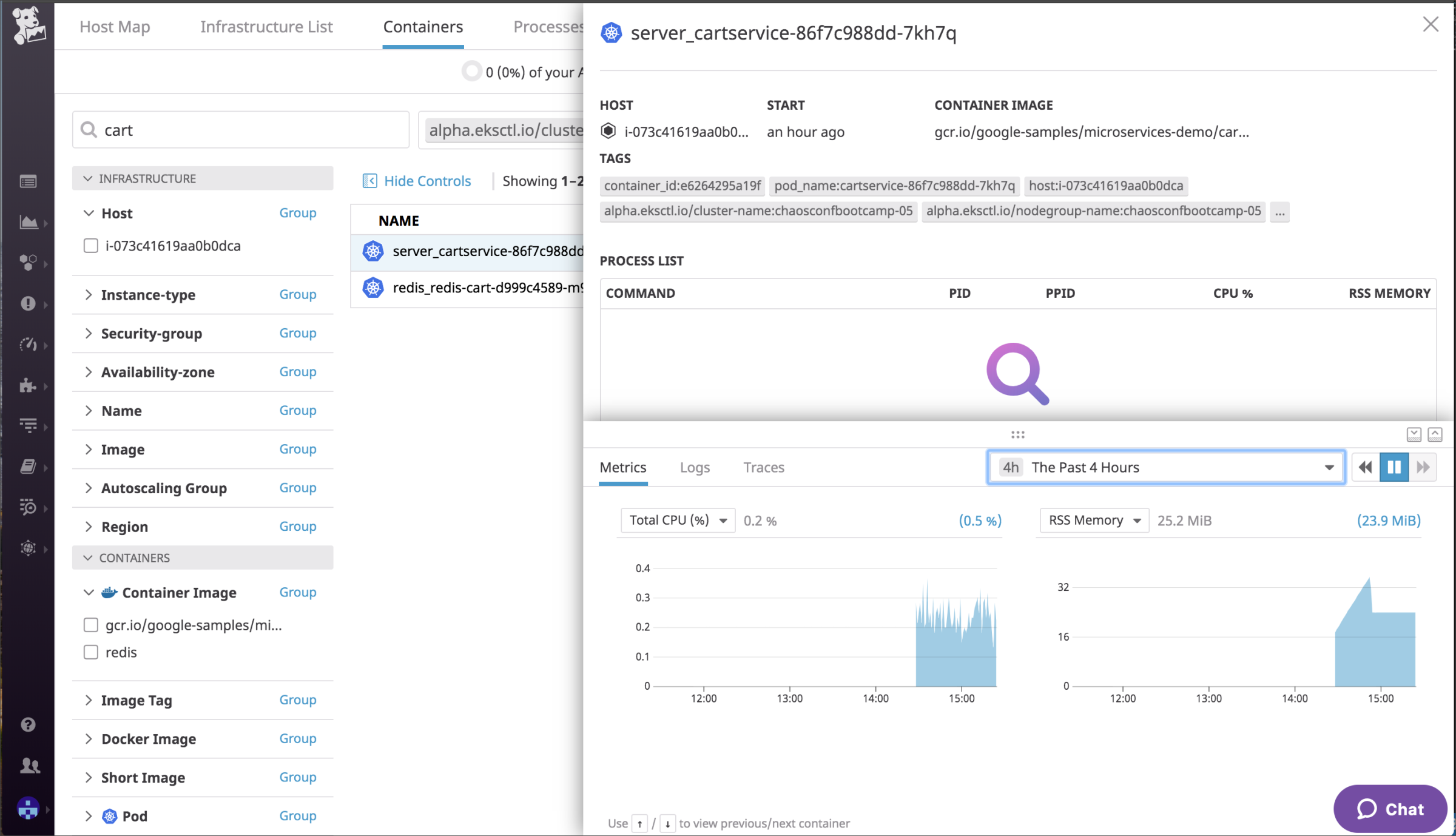
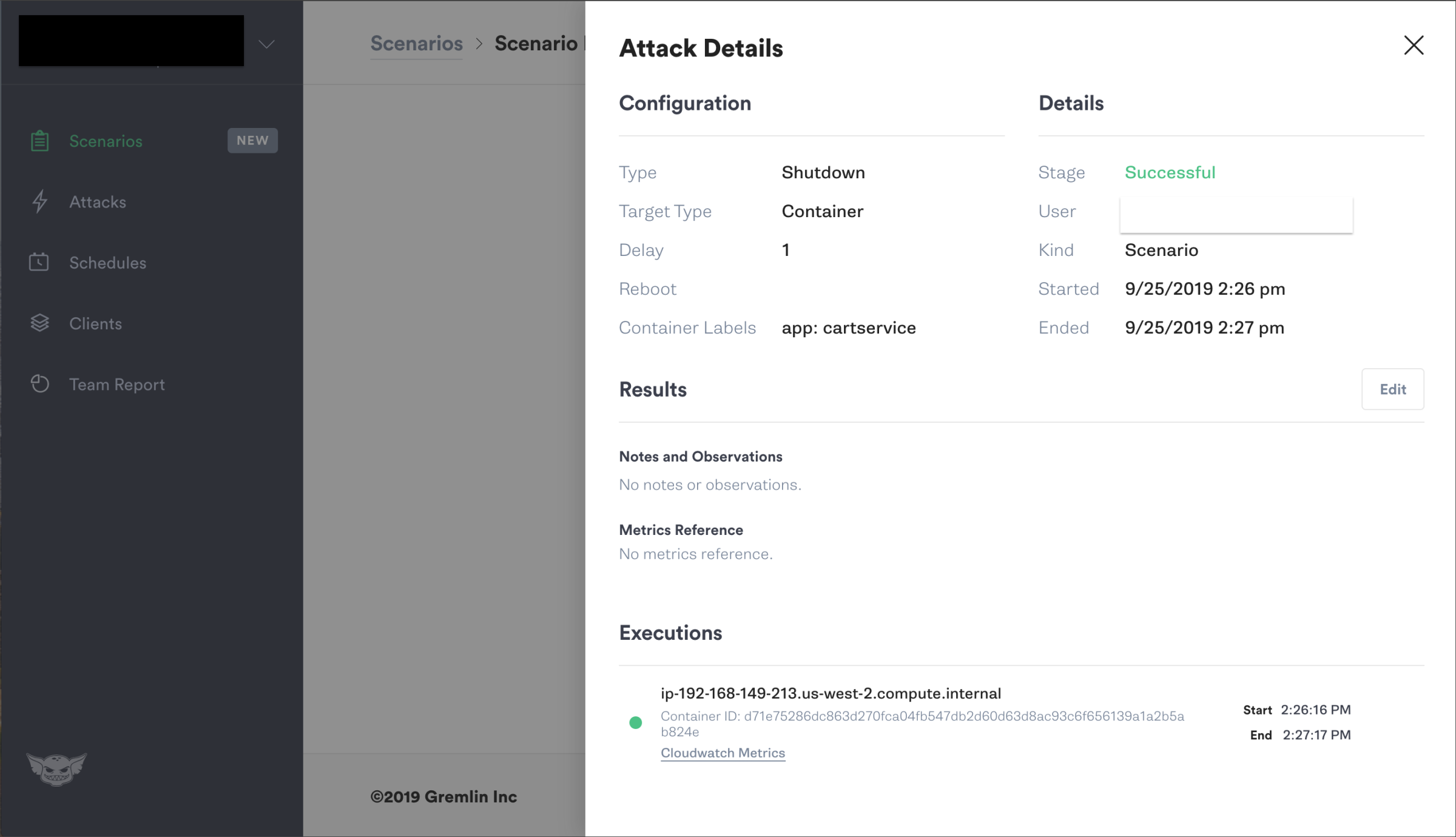
2.特定のServiceにデプロイされたコンテナを停止しても自律的に復旧するか?
次は、先の設計図にあったCartServiceをシャットダウンするというシナリオです。1コンテナをシャットダウンすると、クラスタ内部ではKubernetesによる自己回復が働いて自動的にdesired stateに戻ります。インスタンスのメトリックは無変化でした。この実験自体は平凡でしたが、コンテナが異常停止した場合でも可用性を確保できているかどうかを確認することは、運用視点からすると非常に重要な点だと思います。
3.フロントサーバーへの段階的な遅延の上昇に対してブラウザ上ではサイトが表示されるか?
最後は、先の設計図にある全てのAPIに対して100ms、200ms、500ms⋯⋯と徐々にLatencyを追加するシナリオです。レスポンスタイムを計測する手段がなかったため、ブラウザの開発者ツールで遅延を確認しました。このシナリオでは、遅延が最大で5sまで増加するため、サイト表示に重大な影響を与える結果となりました。少しシナリオが大袈裟でしたが、Service単位のLatency Injectionもできるため、Serviceの追加・更新における遅延を検証する用途では重宝しそうです。
以上、ハンズオンではGremlinのプロダクトを利用してChaos Engineeringを体験しました。仮説、Fault Injection、そして結果検証に至るまでのワークフロー管理をGUIで操作できるため、よく作り込まれたツールであると感じました。
余談にはなりますが、当日のサンフランシスコは最高気温が34℃。会場に空調設備はなく窓は全開で日本ほどの暑さは感じませんでしたが、騒音が常時入り込み、ファシリテーターはマイクなしで説明していたので、正しく聞き取ることはなかなか困難でした。
続いてDay 1です。
Day 1: SESSION

Day 1は、Keynoteが2本、LTが4本、一般が6本という構成でした。登壇企業の業界としては、IT6社、小売3社、アパレル・メディア・旅行がそれぞれ1社で、Eコマース系の会社が目立った印象です。Gremlin,IncのCEOのKolton氏が「今年はWHYではなくHOWにフォーカスしたセッションを用意している」と言っていたように、概念よりも事例がよく聞けたセッションだったかと思います。
今回は私の印象に残ったセッションを3つほど紹介したいと思います。こちらは私の解釈も含まれますので、オリジナルを参照したい方は、セッション動画およびセッションスライドをご確認ください。
“A Roadmap Towards Chaos Engineering” Jose Esquivel, Backcountry
Chaos Engineeringを実現するためのロードマップ、実践する中で見えた8つの安定性のパターン、オブサーバビリティを獲得するための4つの方法を提示していました。パターンが整理されたノウハウの詰まったセッションの一つでした。

Chaos Engineeringを行う前準備として、「Observability」「Alerting」「Incident Management」「Test Harness」が必須であると述べています。中でもObservabilityについては、ログ、トレース、メトリックス、アラートの4つを整備しなければ、本当にchaosな状態になると付け加えています。
では、Jose氏が挙げている8つの安定性パターンについて見ていきます。
- Timeouts & Retries: タイムアウトについては、デフォルトでは長すぎるのでニーズに合わせて適切に設定をするべき。リトライ回数についてはリトライの嵐でTCPやDB接続プールを減少させて影響が出ないよう特に注意が必要である。
- Circuit Breaker: 一定の閾値を超えるリクエストが到達した場合に制限する。
- Bulkhead Pattern: 接続プールにリトライやタイムアウトを委譲してエラーを分離する。
- Steady State: 定常状態を定義する。
- Fail Fast: 失敗は早期に検出する。
- Handshaking: 呼出しを拒否させる。メモリーオーバーフローを回避する。
- Uncoupling via Middleware: 待機が必要な処理をキューに押し出して、他のプロセスが処理できるようにする。
- Test Harness: Unit Testなどに時間を多く割くよりもChaos Testsにジャンプした方が弱点は早く見つかる。
これらは何か設計に悩むような場合にはぜひとも見直したい項目になると思います。特に、タイムアウトとリトライの設定については依存ライブラリに固有の設定があったり、マイクロサービス化が進むと障害ポイントになったりしやすいので、ファーストステップとして確認したいパターンです。
“Forming Failure Hypotheses” Subbu Allamaraju
Subbu氏は組織内でChaos Engineeringを実施して苦悩した経験を話しています。特に印象的な点は、ログやメトリックスはバイアスがかかるから、実際に発生するインシデントが最も学びになる、それ以外にはないと言い切っていました。
彼は、その経験をストーリーで話しています。まずクラウド移行から始まり、障害を前提としたシステムを作るためにChaos Engineeringを導入しました。しかし、チームからは拒否反応を示されたり、ランダムにサーバーを落としても大した発見もなかったり、クリティカルな故障を発生させたくても実問題に繋がるのでできなかったりと、葛藤の日々が続いたそうです。その中で、「システムを不安定な状態でも耐えられる設計にできるか」と考えるよりも「今現在プロダクション環境ではシステムはどういう振る舞いをしているか」を考えるようになったそうです。ドキュメントや図、ログ、メトリックスなどの人間の手でデザインされた眼鏡を通すと本来の姿が隠れてしまうことがあり、システムの現状、「as it is」な状態を見るようになったそうです。
結局のところChaos Engineeringなんて必要ない!? と言いたかったのか真因はわかりませんが、プロダクションのシステムで発生するインシデントが最も学びになることは確かだと思いました。
“Keynote: Chaos Engineering For People Systems” Dave Rensin, Google
人間組織が最も複雑な分散システムであると述べ、分散システムに適用するChaos Engineeringを人間組織に適用したというセッションです。そもそも人間はバグだらけの生物学的なマイクロサービスと定義し直した上で、冒頭で「皆さん左手を挙げてください」と言って壇上から撮影した写真には、右手・両手を挙げる人が何人かいたことを示し、この説を証明していました。

Dave氏がChaos Engineeringを企業に適用したという4つストーリーの中でも、チームメイトから無作為に選ばれた1名に急な近場での休暇(staycation)を取らせるという話は非常に興味深い内容でした。対象者はリモートで仕事をするが、チームメイトからの質問には答えず、ミーティングにも参加せず、メッセージにも反応しません。対象者がその場に存在していなくとも、チームは機能するかどうかを検証するというものです。ひと月に1回、staycationのテストによりSPOF(Single Point Of Failure)が存在しないかをレビューして、SPOFがあるならメンバー間でのナレッジを共有する場を設けるなどして改善をしていったそうです。
Chaos Engineeringをチームビルディングに適用したこの例は、かなり奇抜な印象を受けるものでした。Chaos Engineeringはあらゆる「分散システム」に適用できるという、思考の幅の広がるセッションでした。
以上、Day 1のセッションをいくつか紹介しました。
オフショット

企業のブースも出ていました。朝イチだったので人の入りはまだ少ないです

DevOpsエンジニアが、Oopsしないように(やってしまわないように)というメッセージ

会場では朝食や昼食などが提供。ディナーは撮り忘れました⋯⋯

アフターパーティー。会場中央に巨大なジェンガが設置されており、倒れると「Chaos!!!」と叫ぶ人がいるなど、2日間で最もChaosを感じられる瞬間でした

宿は会場から1マイルほどの場所にAirbnbで取りました。ダウンタウンから離れている閑静な住宅街で、夜は静かに眠れました
終わりに
Day 0、Day 1と参加して、昨年比での参加規模の拡大や登壇企業の多業種化からもわかるように、Chaos Engineeringを実践する企業は広がりを見せていました。「マイクロサービス設計をした上でのChaos Engineering」という風潮も受けますが、3TierでMonolithな構成に適用している事例もあるように、分散システムで冗長構成をとっているシステムであれば適用できるものです。今後はアプリケーションレイヤーにFault Injectionを組み込んだServerlessへの適用事例も増えそうな予感がしています。
また、アマゾン ウェブサービス ジャパン株式会社の畑様のご協力により、Chaos Conf 2019のrecapイベントをAWS Loft Tokyoにて開催することになりました。詳細はこちら
をご覧ください。参加無料ですので、ご興味ある方はふるってご参加ください。
(2019年11月21日追記)
上記Chaos Conf 2019 recapイベント、無事に終了いたしました。当日の資料を下に掲載しております。ご参加いただいた皆さまありがとうございました。懇親会で参加者の方々とディスカッションをして、これまで気づかなかったユースケースやアプローチ手法に関する発見もあり、私にとっても有意義な時間を過ごすことができました。
(2019年12月4日追記)
Chaos Conf 2019 recapイベントで登壇した私を含む3名の講演概要とスライドが「Amazon Web Servicesブログ」で取り上げられています。カンファレンスの内容以外にも、Chaos Engineeringの考え方や、どういったアーキテクチャと相性が良いのかとった視点での学びが得られると思います。是非ご参照ください。