こんにちは、Cygames Research の多胡です。これまで10年以上コンソールゲーム開発を行ってきていて、最近ではハイエンドゲームエンジンを制作しておりました。Cygames でもハイエンドゲームエンジンの開発に携わることになりました。
ゲームエンジン開発を行う上で重要な考え方にデータ指向設計 (Data Oriented Design) というものがあります。今回はこのデータ指向設計を例を交えながら紹介させていただきます。
背景
データ指向設計の考え方は 2009年頃から有名になりました。
この 30年で CPU の性能は1万倍以上になりましたが、メモリの転送速度は10倍にもなっていません。そのため、プログラムのボトルネックはメモリ帯域となることが多くなりました。ゲームにおいても CPU はほとんどの時間がメモリからのデータの転送待ちになっています。CPU の性能を引き出すためには、メモリ帯域をいかに効率よく使うかが重要になっています。
ゲーム業界においては PlayStation3 が Cell プロセッサを搭載していたことも大きな要因だったと考えられます。Cell プロセッサで性能を出すためには SPU の利用が必要不可欠でしたが、SPU のメモリは 256KB しかなく、いかにこの少ないメモリ領域をやりくりするのかが重要でした。
データ指向設計
データ指向設計は、その名の通りデータに着目した設計思想です。プログラムがやることは、データを入力にとって、何らかのデータを出力することです。データ指向設計では、そのデータをどのようにメモリに配置し、どのように読み込み、どのように書きだすのかに着目して設計を行います。
データ指向設計では主に次のようなことを行います。
- データのアクセスパターンを設計する
- データのアクセスパターンに応じてメモリレイアウトを設計する
さらに以下の点も考慮します。
- 複数のインスタンスを同時に処理するように設計する
これは複数のインスタンスを同時に処理するほうが最適化しやすいからです。
CPU とメモリ
メモリレイアウトを設計するためには、ある程度 CPU とメモリの関係を把握しておく必要があります。現在の一般的な CPU は次のような構成になっています。
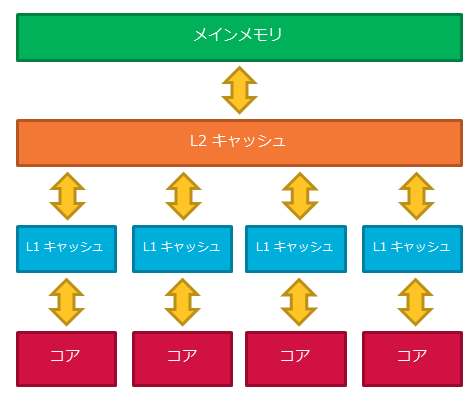
CPU のコアとメインメモリの間には L1 / L2 キャッシュが存在します。(CPUによってはL3キャッシュがあるものもあります。) それぞれのキャッシュ・メモリに対するレイテンシは概ね次の通りです。
| 種類 | サイズ | レイテンシ |
|---|---|---|
| L1キャッシュ | 32KB – 128KB | 3-4 サイクル |
| L2キャッシュ | 4MB – 20MB | 20-40 サイクル |
| メインメモリ | 4GB – 32GB | 200- サイクル |
L1 キャッシュとメインメモリでは 100倍近い速度差があります。
キャッシュラインは 64 バイトですのでデータを読み込むときは 64 バイト単位でキャッシュにロードされることになります。つまり 1 バイトを読み書きする場合でも周辺の 64 バイトをキャッシュにロードすることになります。残りの 63 バイトを利用しない場合は 63 / 64 = 98.4 % のメモリ帯域を無駄にしていることになります。データのメモリレイアウトを設計する場合は、いかに同じタイミングでアクセスするデータを連続したメモリに配置するかということを考慮します。
オブジェクト指向設計 と データ指向設計
オブジェクト指向設計
敵の位置を更新するプログラムについて考えてみます。まず、オブジェクト指向設計で素直に実装すると次のようになります。
class Enemy {
// Move
Vector3 _position;
Vector3 _velocity;
// AI
EnemyAiState _aiState;
// etc
...;
void updatePosition(float dt) {
_position += _velocity * dt;
}
void update(float dt) {
...
updateAi(dt);
updatePosition(dt);
}
};
エネミーの更新を行うプログラムは次のようになります。
Enemy enemies[N];
for (int i = 0; i < N; i++) {
enemies[N].update();
}
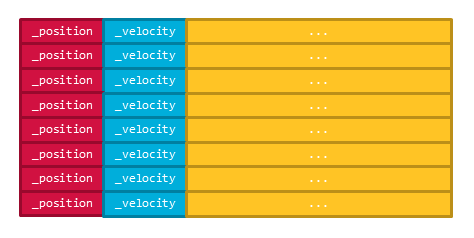
この場合のメモリレイアウトは次のようになっています。
for ループの中でのメモリアクセスではキャッシュラインは次の図のようになります。
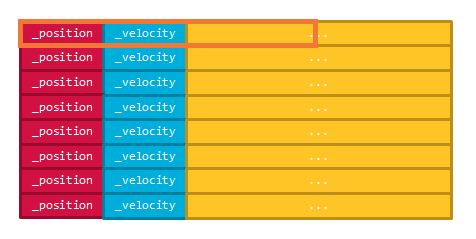
ですので for ループが回るたびにキャッシュミスによるデータの待ちが発生します。
データ指向設計
同じ例をデータに着目して実装してみます。複数のインスタンスの位置更新をまとめて行うとコードをシンプルな状態に保ったままメモリ帯域を効率敵に使えそうです。複数のインスタンスの _position と _velocity をまとめてメモリにレイアウトできるようにEnemy クラスを EnemyMove と EnemyAi に分割します。
class EnemyMove {
Vector3 _position;
Vector3 _velocity;
};
class EnemyAi {
EnemyAiState _aiState;
};
void updateEnemyMove(EnemyMove* moves, int count, float dt) {
for (int i = 0; i < count; i++) {
moves[i]._position = moves[i]._velocity * dt;
}
}
void updateEnemyAi(EnemyAi* ais, int count, float dt);
エネミーの更新処理は次のようになります。
EnemyMove enemyMoves[N]; EnemyAi enemyAis[N]; updateEnemyAi(enemyAis, N, dt); updateEnemyMove(enemyMoves, N, dt);
メモリレイアウトは次のようになっています。
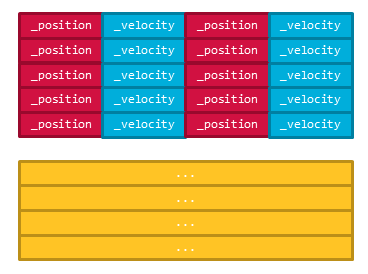
位置の更新時の for ループ内でのメモリアクセス時のキャッシュラインは次の図のようになります。
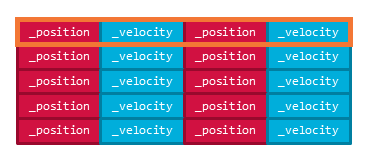
この場合は次の要素のデータまでがキャッシュラインにのるのでキャッシュミスは半分になります。
処理時間の計測結果
それぞれのプログラムを実行した際の位置の更新の処理時間のグラフが次の図です。実行環境は Intel Core i-7 3820K 3.3GHz で、Visual Studio 2015 で /Ox (最大限の最適化) でコンパイルしたプログラムで計測しました。
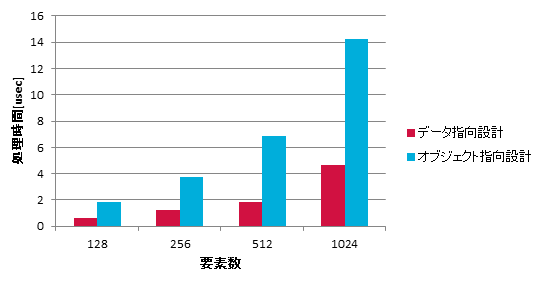
データ指向設計のほうがオブジェクト指向設計にくらべて 3 倍程度高速に動作していることがわかります。
まとめ
データ指向設計について解説を行いました。データ指向設計を行うことで、実行時に高速に動作させることができるようになりました。
データ指向設計について詳しく知りたい方は下記の資料を参考にしてください。
データ指向設計の概略の説明です。
- Data Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP)
日本語の翻訳もあります。
- データ指向設計(またはなぜOOPで自爆してしまうのか)
データ指向設計を実例を交えてわかりやすく解説しています。
- Introduction to Data Oriented Design
CppCon 2014 での Mike Acton 氏によるプレゼンテーション動画です。
C++のカンファレンスで「(C++よりも)C99の方が好きだ」と言ってしまうところが素敵です。
- CppCon 2014: Mike Acton “Data-Oriented Design and C++”
Cygamesではゲーム開発を支える様々な技術研究にも取り組んでいます。
技術研究に興味があるかたは、是非Cygamesで一緒に働きませんか?
採用ページはこちらです。